Whenever I export one of those thousand keyword reports for a gap analysis, I have to take a deep breath before going through the list and navigating through the noise and duplicated intents.

Tired of waiting for my favorite SEO tools to implement a clustering solution, I did it with Python (and a few headaches).
What is keyword clustering?
It’s the process of grouping keywords by cluster. duh. The challenge is to define the type of clusters that would be the most helpful for us depending on our use case.
If you need to cluster by topic/categories and have a limited number of results, you can use manual clustering solutions such as the one explained below. It’s useful to organize your reports, but does not necessarily make the data more actionable.
I’m sure you would find some NLP-powered solutions to define and organize the clusters for you, but the very few solutions I have experimented with only gave me another layer of noise and a margin of error I couldn’t reduce enough to satisfy my needs.
In the context of a gap analysis, you want to cluster your keywords by intent which is what you’d usually do manually.
How to group keywords by intent?
Good news! Google is already doing the heavy lifting with its SERPs, and since you’re trying to reverse-engineer their understanding, it makes sense to leverage that data. Thankfully, SEMrush provides the ranking page along with the position (AHREFs only provides the position), so you don’t have to scrape Google SERPs yourself.
Based on the data available, we can calculate the overlap of URLs in the SERPs: if a query generates a similar-ish response, it’s fair to assume they are the same-ish intent. After a few tries, I defaulted for my script to look for three or more similar URLs in the SERPs.
The Process
As an example, we’ll use the same dataset I used in other gap-related posts: SEMrush gap for space.com
Those are the steps of the process:
- 1. Merge and check the data sources: I often export multiple CSVs from SEMrush to have more targeted gaps instead of one big pile of data. That process turns those well-thought-out exports into… one big pile of data.
See Also: CSV Magic, basic operations with Python/Google Colab - 2. Clean the data: Remove duplicates (because of the merge), and queries with a date.
Also filters out anything that doesn’t contain a clear intent word as defined by the following regex
intentregex = r'\b(?:what|where|how|why|when|is|does|are|worth|can|should|would|best|most|top|vs|versus|tutorial|diy|make|build|difference|compar(ison|ed)|reviews*)\b'- 3. Calculate the gap type (as defined in the previous post, replicating what SEMrush doesn’t provide in the export but only in the UI… yeah annoying)
#myrank -> best position for my domain
#comp_min_rank -> best position for competitors domains
conditions = [
(my_rank == 0) & (comp_min_rank < 50),
(my_rank > 12) & ( comp_min_rank < 50),
(my_rank < 12) & (my_rank > 0),
(comp_min_rank > 50)
]
values = ['untapped', 'weak', 'skip - not a gap', 'skip - comp not ranking']- 4. Calculating the overlap (aka magic): Finding the most efficient method gave me a few headaches. I could not find a possible vectorization and ended up using a loop (of shame) through the data frame until it ran out of rows, eliminating the keywords already assigned after each pass. It’s long and inefficient, but it works.
The needle is the first row, the haystack is the rest. If two rows have three or more URLs in common, the value of the “keyword” column of the needle is assigned to a “main keyword” column of the matching row.
The Results
- We started with a CSV containing 50k keywords.
- Cleaning up the data to keep only keywords with an intent left us with 11,3k keywords.
- We end up with 2,300 clusters which is way less overwhelming and very actionable.
(Link to the spreadsheet)
- Main Keyword is the keyword with the most search volume, and the name of the cluster as we defined it.
- SUM of Search Volume is the sum of the MSV of all keywords in the cluster. It’s wrong but good directional data
- COUNT of Keyword is the number of keyword variations in the cluster, which can also be used to prioritize
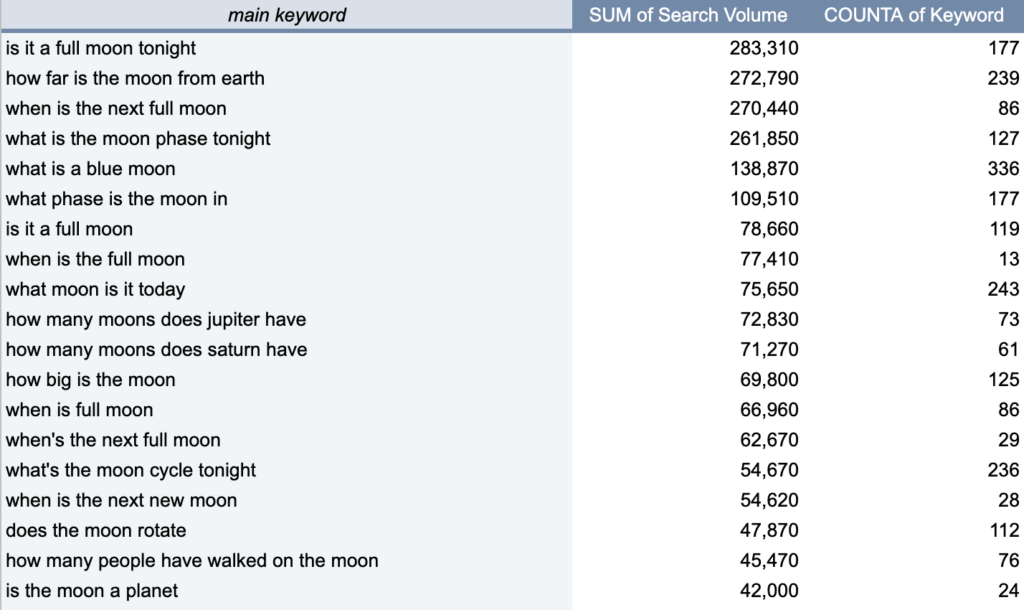
If we dive into the details, you can see in the following examples, the results are pretty darn good:
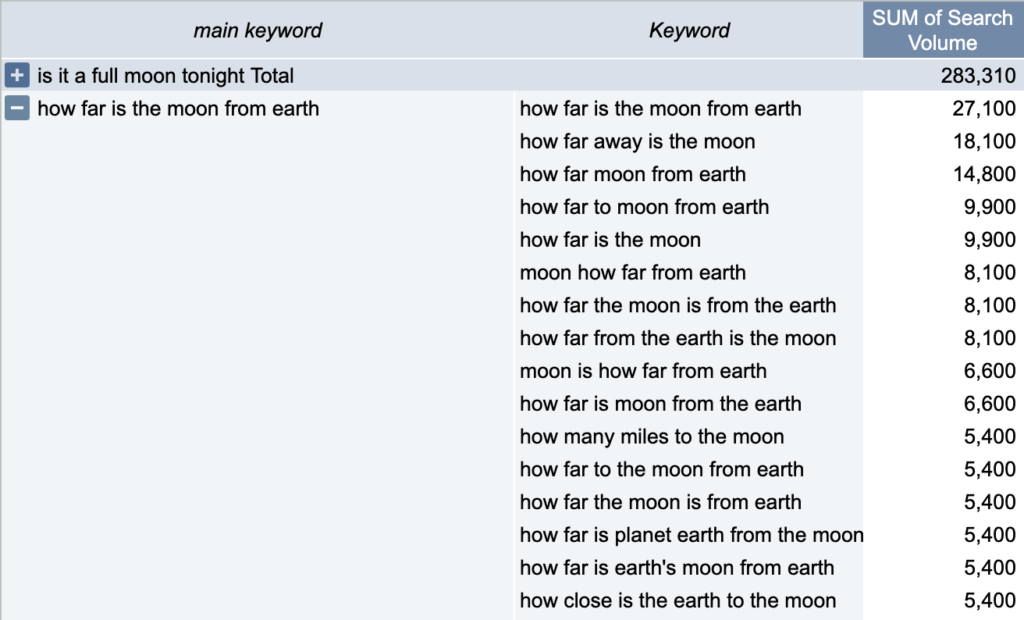
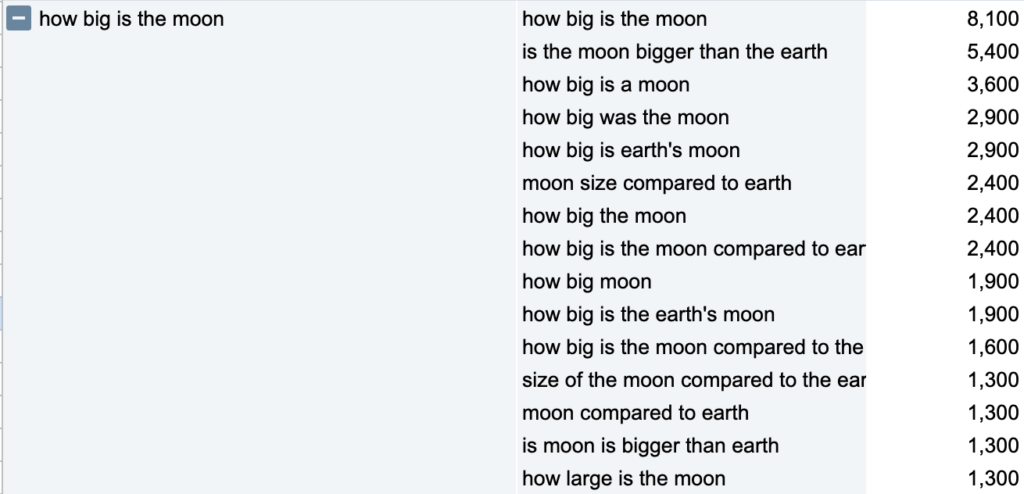

I’m not able to share the complete code for now. It only runs locally and have yet to be cleaned up. I will try to make it more generic (as is, it does some tasks very specific to my brands) and see if Colab can handle it, then share it here.
Maybe if you ask chatGPT it will spit you a better script than mine 🙂 or even better ask your customer success manager at SEMrush or AHREFs to do it for you. It’s so easy to do that I have a hard time understanding why it’s not already a feature.
It is actually a feature offered by “Keyword Insights” (see below). I don’t know them or the solution, and can’t recommend it but I came across their post this week and it actually triggered the writing of mine as they are using the same approach. My guide will hopefully be the second best keyword clustering guide in the universe. Or at least top 5, out of modesty.
Read Also:
Was this helpful?
0 / 0

SEO/Data Enthusiast
I help international organizations and large-scale websites to grow intent-driven audiences on transactional content and to develop performance-based strategies.
Currently @ZiffDavis – Lifehacker, Mashable, PCMag
ex @DotdashMeredith, @FuturePLC